Abstract#
The purpose of this essay is not to convince anyone that the current paradigm of software engineering requires fundamental change, but rather to encourage engineers to reconsider their entire toolchain and examine how previous programming decisions impact code production practices. This essay provides a potential framework for thinking about tech stack decisions in the age of autonomous code-producing machines. As large language models demonstrate increasing proficiency in code generation, we should reassess what it means to engineer software, where technical debt originates, and how we can architect systems that treat natural language as a first-class programming interface.
The Evolution of Development Velocity#
Software development has undergone several paradigm shifts in how we manage the trade-off between velocity and quality. The Waterfall methodology, introduced in 1970, treated development as a sequential process where problems found late could cost orders of magnitude more to fix than early detection.1 Then came Agile: in February 2001, developers met at Snowbird, Utah and created the Manifesto for Agile Software Development, emphasizing individuals over processes, working software over documentation, and responding to change over following plans.2 This shift allowed businesses to iterate faster, receive feedback continuously, and adapt to market demands with minimal friction.
Yet one constant persists: technical debt. The persistent reality that choices made today impact our capacity for technical decisions tomorrow. There exists a general consensus that proper software development involves trade-offs between accumulating tech debt and the velocity at which businesses design and implement customer solutions. I believe this trade-off will forever characterize software engineering. But 2025 has been proclaimed by many as the year of the agents—autonomous programming systems that aid developers in code production. Substantial debate surrounds code quality and improvement strategies. What I have yet to encounter is reflection on how these agents might fundamentally alter the economics of that trade-off, potentially introducing a new paradigm comparable to the shift from Waterfall to Agile.
Consider this: if documentation becomes execution, if natural language instructions reliably produce working code, then velocity transforms entirely. The question becomes not “how fast can we write code?” but “how fast can we document what we want, and is our tech stack configured to accept natural language as instruction?” This is Agile on steroids—a potential methodology where the primary constraint is the clarity of your requirements and the determinism of your validation systems. Your tech debt becomes the friction in this translation process.
Natural Language as a Programming Paradigm#
A large language model functions as a statistical black box that accepts human language in any form as input—including human language as a superset of programming languages. These models understand both natural language and every programming language devised by man. While this is not a revolutionary insight, what appears forgotten is how human language can be properly leveraged as a programming interface.
Software engineering, as I understand it, is the practice of translating a constrained set of business ideas into programmatically executable software that meets customer requirements. As any experienced developer will attest, how you accomplish this depends on selecting the right tool for the job. The question is whether we are still using the right tools given this new natural language programming paradigm.
I reflect on the famous “Atwood’s Law” proposed by Jeff Atwood a co-founder of Stack Overflow: “Any application that can be written in JavaScript, will eventually be written in JavaScript”. I interpret this as recognition that JavaScript represented, at the time, the most comprehensible programmatically executable language invented—it was easy to read because most software was written in nearly plain English. It was easy to build a company around, and thus we saw the javascript ecosystem flourish. But as history demonstrated, JavaScript alone was insufficient. The loosely typed system demanded deterministic additions, leading to TypeScript’s invention to leverage flexibility while attempting to mitigate pitfalls.
This shift toward natural language does not, as some might hope, eliminate the “essential complexity” that Frederick Brooks described in No Silver Bullet—the inherent difficulty of designing complex logical systems. Rather, it represents the ultimate tool for automating the reduction of “accidental complexity”. If the history of software engineering is a long war against the friction of syntax, memory management, and build tools, then the programmable engineer is our most powerful weapon yet. By delegating the “accidental” labor of code production to an agent, the human engineer is finally unburdened from the minutiae of implementation. However, this creates a new urgency: when the cost of clearing accidental complexity approaches zero, the “essential” debt of our architectural decisions becomes the only remaining bottleneck. Our tech debt is no longer just “messy code”; it is a navigational hazard that prevents the agent from accurately mapping our intent to the machine’s execution.
The Black Box and the Robot: Understanding Agent Architecture#
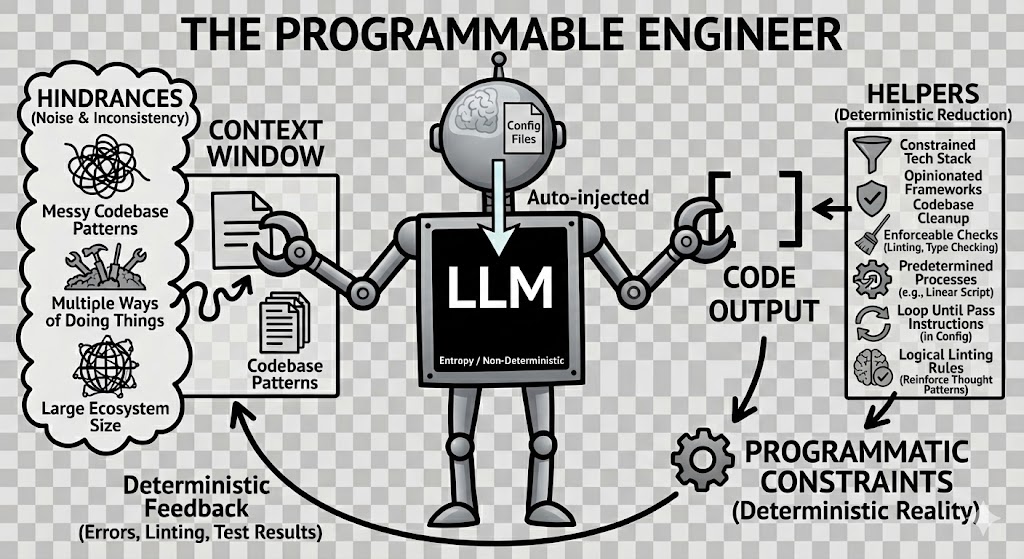
A typical developer workflow now involves typing or speaking to a programming agent, expecting it to do what we say and write code as we would. This agent is not merely a large language model—the model serves as the black box, while the agent is a mechanism containing that black box that loops through it given an objective. Think of it as a cartoon robot with a black box in the center of its belly. The robot has arms. An agent uses its arms to grab pieces of context and feed them into the black box, producing code that meets the criteria of the input.
A Brief Technical Primer#
To understand how agents actually work, we need to clarify what that “black box” really is and what gets fed into it. The context window is the input into the black box—it’s everything that gets packaged up and sent to the large language model for processing. Large language models are fundamentally stateless—they possess no memory between interactions.3 Each time you send a message to an agent, the entire conversation history, all accumulated code snippets, tool outputs, and configuration files must be sent fresh to the language model. The model doesn’t “remember” your previous messages; it’s being reminded of them with every single request.
This context window is measured in tokens (roughly equivalent to words), and it has a size limit. Modern models like Claude can handle hundreds of thousands of tokens, but every token costs money and processing time. More importantly, this stateless architecture is why context management becomes critical. When you use an agent, configuration files like .cursorrules or claude.md are automatically injected into the context window with every request. When you enable MCP servers, those tool definitions are also added and consume the available tokens in the context window. When the agent reads your codebase, or calls an mcp tool, that code fills the context window. Every interaction is a fresh calculation based entirely on what fits in that window at that moment.
This is why both layers of control matter: natural language instructions guide what the agent’s “arms” grab and put into the context window, while programmatic constraints validate the output after it emerges from the black box. The agent loops—grabbing context, filling the window, getting a response, executing tools, and repeating until the task is complete.
Controlling the Entropy#
This is inherently a non-deterministic function. Large language models are fundamentally random statistical calculators, but that randomness is controllable by the input. If you envision that robot with its black box belly as an engineer with a PhD in pattern recognition, interesting scenarios emerge. The distinction is important: pattern recognition rather than software engineering. This framing helps clarify the relationship between three entities: the software engineer operates the agent, the agent leverages the large language model to pick tools, and the entropy mechanism resides within the model itself on api calls to the LLM provider. Understanding this hierarchy reveals where we can impose control and where inherent uncertainty remains.
I believe we can place sufficient restrictions and guardrails on the agent such that the entropy shrinks to an acceptable level. Given the right tech stack, documentation, and communication practices, we can effectively mitigate the randomness of the system. If this is possible, could we not scale this idea significantly? Could we not have multiple programmable engineers producing desirable code simultaneously? Would it not follow that the software engineer, now unburdened by the task of writing code, would have more time to contemplate the translation process, customer requests, testing mechanisms, and actual implementation of each feature?
In this framing, deterministic validation and testing harnesses do more than verify correctness; they function as entropy- and hallucination-reduction mechanisms by confronting agent output with unambiguous programmatic reality.
Two Layers of Agent Control: Connecting the Ligaments#
There are two ways to constrain an agent: from within the entropy system and from outside it. Both are necessary. The combination creates what I call the ligaments—the connective tissue between flexible natural language instructions and rigid programmatic validation.
The industry has embraced natural language instructions embedded in configuration files. Six months ago, I wrote an essay called “Operator|Contract|Workflow” proposing exactly this: markdown files that instruct agents how to behave. These files are injected into the context window with every request, providing consistent guidance. But natural language alone is insufficient. The model has seen countless different ways to solve the same problem in TypeScript, countless different libraries and frameworks, countless different architectural patterns. This abundance becomes noise when you’re trying to establish consistent patterns in your codebase. The solution is half-baked.
The correct combination of both layers creates the programmable engineer. Natural language instructions guide behavior within the black box. Programmatic constraints—linting, type checking, compilation, testing, shell scripts, API integrations, patterns, programming practices—provide hard boundaries outside it. When an agent receives an error from the compiler, test suite, or validation script, that feedback is deterministic. It’s not asking the model to remember instructions; it’s confronting it with programmatic reality. In addition, clever ideas like hooking into the file creation process and enforcing a file naming pattern on creation. Or utilizing your project management tool for your code branching strategy and developer workflow.
This dual-layer approach also avoids context bloat. Rather than cramming thousands of lines of instructions into markdown files or relying on injected approaches like Model Context Protocol (MCP) that hide complexity, we use small, repeatable scripts and integrations that both humans and agents can execute. The Linear script is short and the validation hooks come out of the box with Cursor Agent. The linting rules are standard configurations. Each piece is comprehensible, debuggable, and deterministic. The ligaments are visible.
Reimagining Technical Debt: The New Economics of Simplification#
If producing high quality code is getting cheaper—where does the cost live now? Does it live in the bugs? The logical errors, the edge cases missed, the sloppy patterns that compound over time. Whether those bugs come from human programming mistakes or from agents producing code that compiles but doesn’t quite capture the intent, the result is the same: we spend significant time debugging, fixing, and maintaining.
This changes how we should value technical debt. Traditional tech debt calculations weigh the cost of complexity against the speed of delivery. Move fast, accumulate some mess, pay it down later when it becomes painful. But if code production approaches zero cost while bug fixing remains expensive, does the equation shift dramatically?
Consider tech debt that stems from overcomplicated architecture, inconsistent patterns, or sprawling dependencies. Cleaning up that kind of debt has always had value—it makes the codebase more maintainable for human engineers. But now it has double the value: it simplifies things for human engineers and for an infinite number of programmable engineers. When you consolidate three different ways of handling react state management into one clear pattern, you’re not just making it easier for your team to understand. You’re making it possible for the agent to identify a single, consistent rule that will be followed reliably in its area of work.
The ROI calculation on simplification work changes completely. Refactoring to reduce dependencies? That’s not just technical hygiene anymore—it’s infrastructure for agent-driven development. Establishing clear architectural boundaries like “only the repository layer touches the database”? That’s not just good practice—it’s a constraint that both humans and agents can validate programmatically. Choosing an opinionated, batteries-included framework over a flexible but complex one? That decision now impacts whether your agents can reliably navigate your codebase or constantly produce variations that require human review.
Technical debt becomes a question of navigability. Can a human engineer—or an agent—look at your codebase and quickly understand the patterns? Can they predict how to fetch data from a client component, how that data flows through layers, what conventions govern naming and structure? If the answer is no, if inconsistency and complexity create friction, then every piece of code produced—by human or agent—carries a higher maintenance burden.
The cost-benefit analysis weighed with most technical decisions needs adjustment to reflect this new reality. Writing high-quality code is becoming inexpensive. The most expensive component of software development has been paying engineers to fix bugs. But if we have programmable, scalable engineers capable of producing code at the level of the rest of the team, then the job of software engineers becomes thinking about problems and documenting software behavior, rather than getting mixed up in the minutiae of code styling, formatting, placement, and naming. Engineers should be positioned to think about business problems and how to solve them with software, not software problems and how they impede the business.
This is not a call for perfection or premature optimization. It’s a recognition that the economics have shifted. Complexity that was once tolerable because “we’ll fix it when it breaks” becomes intolerable when it multiplies the surface area for agent-produced bugs. Simplification that was once nice-to-have might become essential infrastructure. The programmable engineer amplifies whatever state your codebase is in—if it’s simple and consistent, you get reliable output; if it’s complex and inconsistent, you get unreliable output at scale.
A Different Perspective#
This represents a fundamentally different way of viewing our current environment. My opinion is that the current state of software is generally unhealthy. Applications require constant updates before they function. They are slow, consume substantial resources, and require significant capital to maintain.
However, approaching code production from an English-first perspective—a naturally human approach—provides us a way of reevaluating our businesses from the ground up. While it will always remain true that an engineer’s job is to read code and make sure it behaves as the customers require, I no longer believe it is the job of the engineer to write all of their code.
Some years ago, machine learning algorithms were trained to scan radiology imagery and identify potential health issues in patients. These algorithms became so proficient that modern radiology imaging can detect anomalies better than most human radiologists. At the time, this frightened many people, and there were fears the radiology profession would disappear. Several years later, there are more radiologists than ever. This is because the job of the radiologist is to detect and investigate potential diseases, not to look at imagery. Looking at imagery is a task of the radiologist, much as writing code is a task of the software engineer. I believe we are at an opportune position in technology and AI progress where we as engineers should take honest time to reevaluate what it means to write code, what it means to engineer and architect software, and potentially rebalance our mental perception of tech debt, how rapidly it accumulates, and what it truly costs us.
Conclusion: A Call to Reflection#
This is not a call to action for drastic changes in your codebase. This is a call to action for reassessment of what we do on a daily basis. How much time do we spend developing patterns and abstractions around our tech debt, around our dependencies, around our ecosystem issues? If producing code is now substantially less expensive, then many new doors are available and many new levers exist to make translating business ideas into programmatically executable code more efficient.
The implications are profound. If we can construct systems where natural language serves as a reliable programming interface, constrained by recognizable patterns and validated by programmatic checks, then the nature of technical debt itself transforms. It is no longer solely about the code we write today limiting our options tomorrow—it is also about the systems we design today limiting our ability to instruct agents tomorrow. The tech debt of the future may be measured not in lines of code requiring refactoring, but in the comprehensibility and consistency of our architectural patterns, the clarity of our documentation, and the determinism of our validation systems.
This essay does not provide definitive answers. Rather, it poses a question that I feel demands serious contemplation from every software engineer: as the cost of code production approaches zero, what becomes valuable? I propose that what becomes valuable is not the ability to write code, but the ability to think clearly about problems, to architect systems that are comprehensible to both humans and machines, and to translate business needs into specifications that can be reliably executed by increasingly capable autonomous agents. The tools are changing, and we must consider whether our thinking should change to match.
Bibliography#
Atwood, Jeff. “Atwood’s Law.” Coding Horror (blog). July 17, 2007. https://blog.codinghorror.com/the-principle-of-least-power/.
Brooks, Frederick P., Jr. “No Silver Bullet—Essence and Accidents of Software Engineering.” Computer 20, no. 4 (April 1987): 10–19. https://doi.org/10.1109/MC.1987.1663532.
